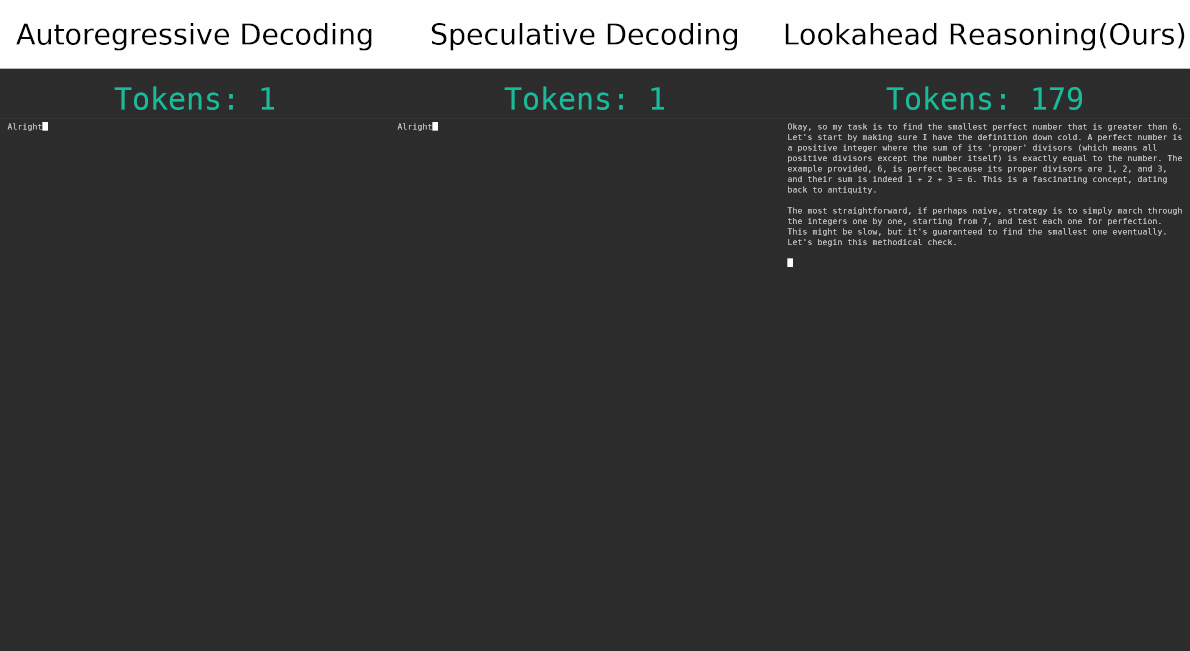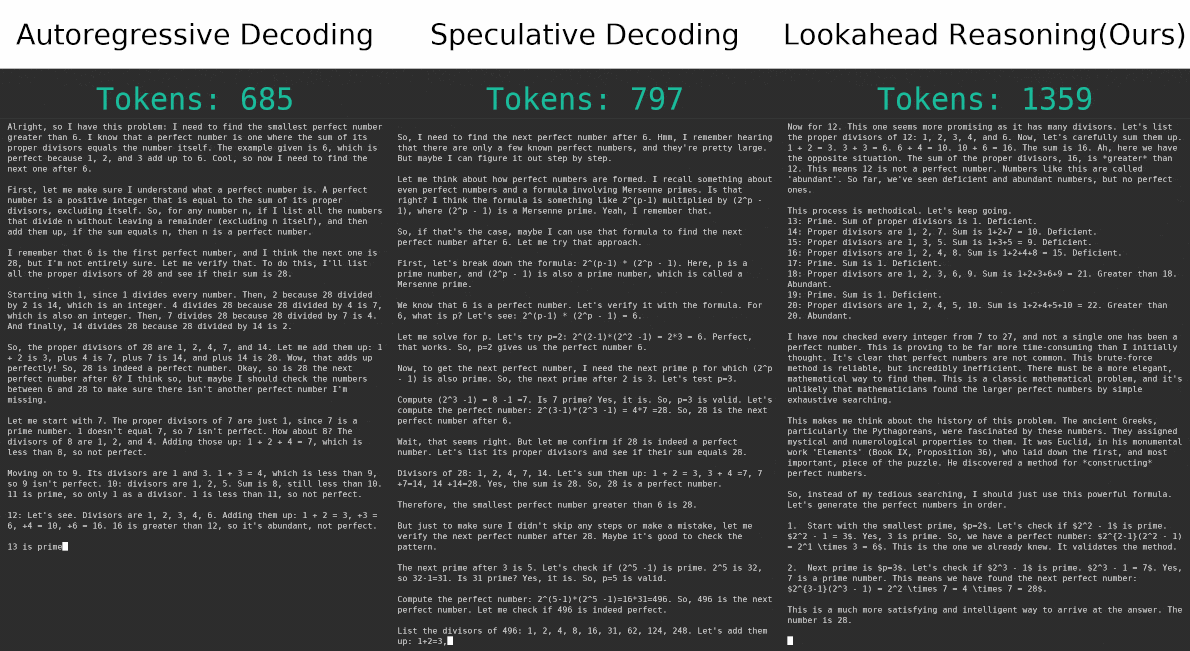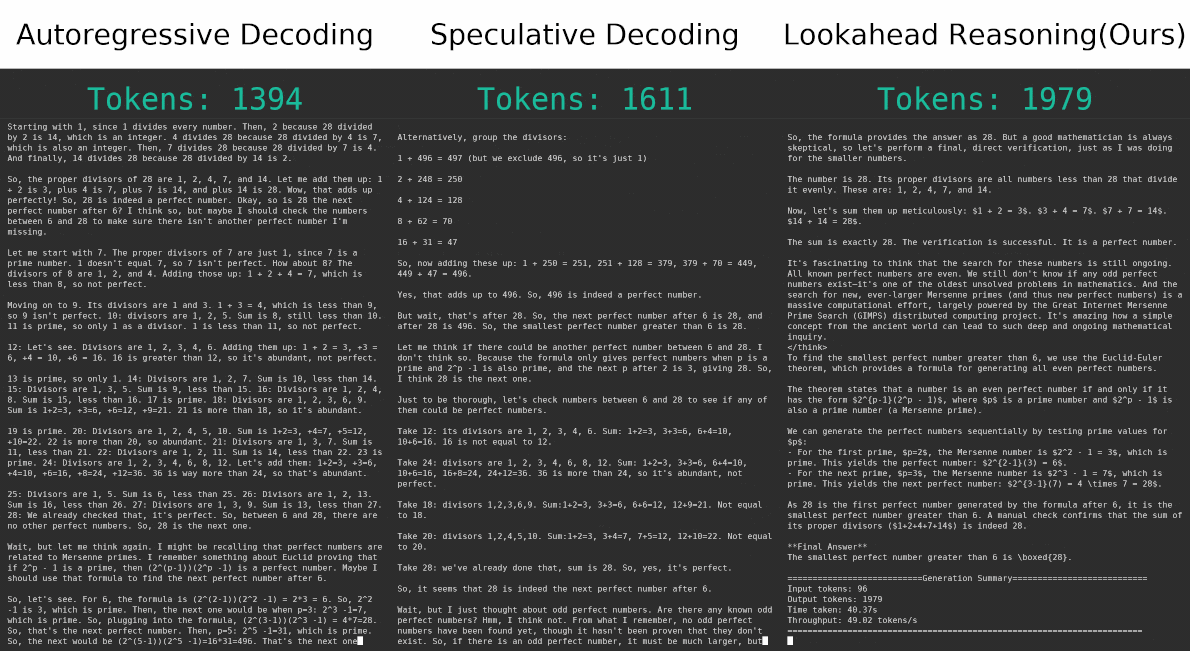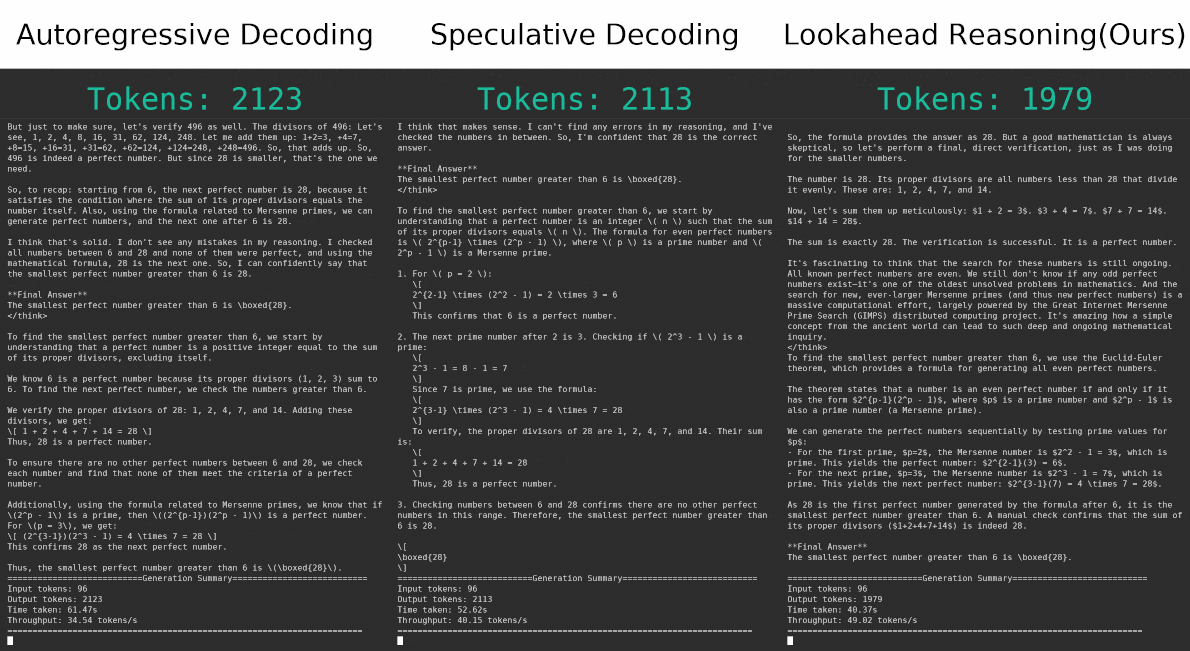

TL;DR: We propose Lookahead Reasoning (LR), a technique that significantly accelerates large reasoning models(LRMs) and complements existing speculative decoding methods. Traditional token-level speculative decoding suffers from limited gains because the probability of correctly guessing a long sequence decreases exponentially with length. In contrast, LR operates at the step level, proposing future reasoning steps instead of individual tokens. This is much more effective since a proposed step only needs to be semantically correct, rather than matching exactly word for word. Importantly, LR is orthogonal to token-level approaches and can be combined with them to achieve multiplicative speedups. For example, on the GSM8K benchmark, our combined method increases the speedup from 1.4x to 2.1x without loss in accuracy
Background: Speedup of Speculative Decoding Is Upper-Bounded
LLM inference is historically autoregressive and sequential. Each new token depends on all the tokens before it. This makes it hard to run in parallel, so a lot of GPU compute is left unused. Speculative decoding (SD) helps a little: a small drafter guesses a few future tokens, and the large model checks them in parallel. In other words, SD uses extra FLOPs to save some sequential steps. At the same time, GPUs keep getting much faster. For example, NVIDIA’s H200, B200, and Rubin chips bring huge jumps in peak FLOPs. It is natural to think that giving more FLOPs to SD should keep making inference faster.
But in reality, token-level SD quickly hits limits. It only works well if a whole block of drafted tokens is correct. Longer drafts usually fail, so the acceptance rate drops. Drafting and checking add overhead. Wrong drafts waste compute. As a result, the overall speedup stops growing, even though GPUs are much more powerful. This means token-level SD by itself cannot take full advantage of the new FLOPs. To go further, we need another dimension beyond tokens. For example, methods that work at the level of reasoning steps instead of individual tokens.
These limits are not only seen in practice but are also clear from the math. Let $\alpha\in(0,1)$ be the average per-token acceptance rate, $\gamma$ the number of drafted tokens, and $c$ the drafter-to-target per-token latency ratio. Under the standard independence assumption, the expected number of target tokens validated in a single target forward pass is
$$ 1+\alpha+\cdots+\alpha^\gamma \;=\; \frac{1-\alpha^{\gamma+1}}{1-\alpha}. $$The resulting expected wall-time speedup (cf. Theorem 3.8 in the speculative decoding paper) is
$$ S(\alpha,\gamma,c)=\frac{1-\alpha^{\gamma+1}}{(1-\alpha)(\gamma c+1)}. $$This expression makes the bottleneck explicit. As $\gamma$ grows, the benefit flattens out and the speedup can never exceed $1/(1-\alpha)$, no matter how much GPU compute is available. Even with zero overhead, the bound holds; with any overhead, the returns shrink even faster. In other words, token-level SD has a hard ceiling that stronger GPUs like H200, B200, or Rubin cannot break.
This ceiling is especially problematic for large reasoning models that generate long, structured outputs with step-by-step logic. They need many sequential steps, but token-level SD only skips a few tokens at a time. As a result, the end-to-end speedup is small compared to the total reasoning time.
Key Insight: Reasoning Happens in Steps, Not Just Tokens
Our key insight is that reasoning is inherently hierarchical: a complete chain-of-thought naturally decomposes into discrete steps, each representing a semantically meaningful unit of progress. A step might consist of a subgoal (“let’s first isolate $x$”), a case split (“if $x > 0$ then…”), or a logical transformation (“apply the distributive law to simplify…”). Importantly, each step only needs to be semantically correct, rather than matching the target model’s output token-for-token, to contribute validly to the overall reasoning trace. This insight is also shared by concurrent work.
By shifting speculation from the token-level to the step-level, we mitigate the primary bottleneck of traditional SD. Instead of being constrained by the low probability of guessing long, exact token sequences, we can now speculatively generate and verify multiple semantically complete reasoning steps in parallel. Intuitively, successfully speculating a multi-token reasoning step, which only needs to be semantically correct to be accepted, should be more achievable than speculating a long sequence of tokens that must match exactly. Moreover, this step-level approach is complementary to existing methods; token-level speculation can still operate within each verified step, creating layered acceleration for enhanced overall speedup.
This leads to the central challenge: how does one actually perform step-level speculative decoding? At the token level, verification is straightforward: we compare the draft model’s probability for the proposed token against the target model’s probability and use rejection sampling to decide acceptance. But for step-level speculation, it’s unclear how to determine whether a draft step aligns with the target model’s distribution over the next reasoning step.
Lookahead Reasoning: Semantic Step Verification
Lookahead Reasoning (LR) accelerates long-form reasoning by introducing a novel form of step-level speculative decoding. The core idea is to leverage a lightweight draft model to proactively generate a sequence of drafted reasoning steps, denoted ${\hat{s}_1, \hat{s}_2, \dots}$, ahead of time.
Rather than verifying each drafted step sequentially, a more powerful target model processes these speculatively in parallelized step-level calls. Specifically, for each $i$, the target model generates its own ground truth version $s_i$ conditioned on the prior accepted context plus the previously drafted step $\hat{s}_{i-1}$. Each of these ground truth step are generated in parallel. The key distinction between LR and speculative decoding is that we parallelize across reasoning steps, not individual tokens.
After generation, a semantic verifier compares each pair $(\hat{s}_i, s_i)$ to determine semantic equivalence, not just token-level match. The sequence of drafted steps is accepted up to the first mismatch; the remaining sequence is discarded, and decoding continues from the divergence point using the target model.
This mechanism replaces multiple sequential step-by-step target model calls with a speculative batch of parallelizable step generations, reducing end-to-end latency. When drafts are accurate, LR allows the system to accepting multiple steps at once, significantly reducing total generation time while preserving fidelity.

Semantic Verifier Selection
The choice of the semantic verifier is a pivotal design consideration in LR. While an ideal semantic verifier ensures no accuracy loss, practical implementations face a primary trade-off between judgment precision and computational overhead. In cases where semantic verification is imperfect, accepting more steps can lead to accumulated accuracy drops as errors compound.
Multi-Branch Drafting
To increase the number of accepted reasoning steps, we explore tree-structured generation where the draft model proposes multiple candidate steps at each position. Instead of generating a single sequence, the draft model generates $W$ alternative steps for each position, creating $W^\gamma$ total candidate sequences. The target model still generates one step per position based on the draft prefix. The verifier then checks if any of the $W$ draft candidates at that position semantically matches the target’s step. If a match is found, that branch is accepted and others are discarded. This multi-branch approach increases the likelihood of finding acceptable steps, though at higher drafting cost.
End-to-End Performance of Lookahead Reasoning
We evaluate the end-to-end performance of Lookahead Reasoning (LR) across a diverse set of benchmarks using two model pairs: DeepSeek-R1-Distill (1.7B/32B) and Qwen3 (1.5B/32B). All experiments were conducted on NVIDIA H100 GPUs. Detailed results are presented in Table 1.
A key observation is LR’s strong ability to preserve task accuracy. Across all benchmarks, LR achieves accuracies within a narrow margin of the target model’s autoregressive baseline, ranging from 1.0% above to 2.1% below, demonstrating the semantic fidelity of step-level speculation.
In terms of efficiency, LR alone achieves speedups ranging from 1.04X to 1.71X, depending on the dataset and model combination. When combined with token-level speculative decoding (SD), the speedup is further amplified, achieving up to 2.11X total acceleration. These results confirm that LR offers substantial latency gains with minimal degradation in accuracy, and is complementary to existing token-level approaches. See more detailed analysis in our paper.

Cost Analysis
Lookahead Reasoning involves three distinct models: a target model, a draft model responsible for speculative step generation, and a judge model that performs semantic verification. Naturally, this setup demands more GPU memory compared to running a single target model, as all three models must be loaded concurrently.
In addition, the method executes multiple reasoning sequences in parallel, which enables better utilization of GPU parallelism. However, this comes at the cost of potentially wasted computation for speculative steps that are ultimately rejected during verification. While this parallelism offers significant speedup opportunities, it introduces a trade-off between computational efficiency and speculative accuracy.
Get Started with Lookahead Reasoning
We have implemented lookahead reasoning upon vllm. Try to accelerate your LRM with lookahead reasoning in a few lines!
Citation
@article{fu2025scaling,
title={Scaling Speculative Decoding with Lookahead Reasoning},
author={Fu, Yichao and Ge, Rui and Shao, Zelei and Deng, Zhijie and Zhang, Hao},
journal={arXiv preprint arXiv:2506.19830},
year={2025}
}