Can RL-based LLM post-training on games generalize to other tasks? (GRL)
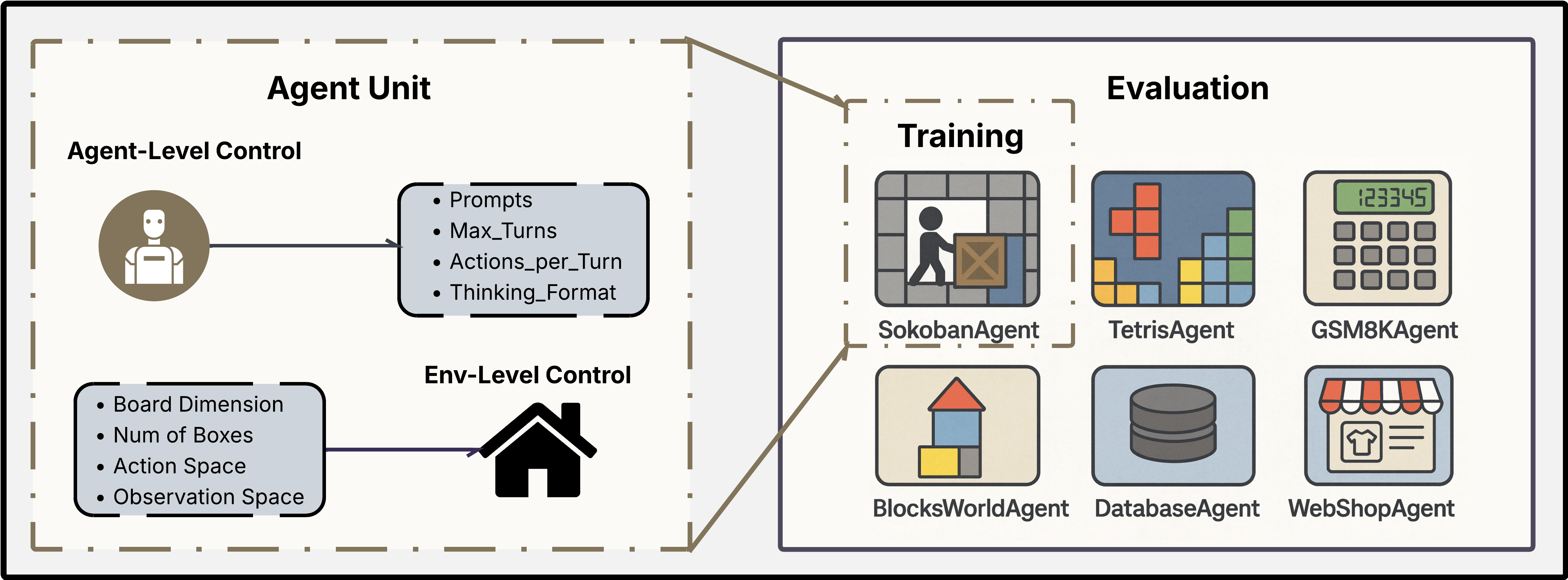
Post-training LLMs on games (Sokoban, Tetris) improves same-family variants (≈ +2–56%) and shows smaller gains on related tasks (Blocksworld +3–7%, WebShop ~+6% but unstable); no improvement on GSM8K. We introduce GRL, an agent-centric, multi-turn RL framework that makes LLM–environment interaction highly customizable for systematic generalization studies.